

【钛媒综合】AI 和人类的较量再一次展开了。
1月28日上午消息,谷歌今日召开全球电话会议,旗下Deep MInd创始人戴密斯·哈萨比斯(Demis Hassabis)宣布了谷歌在人工智能领域的重要进展:开发出一款能够在围棋中击败职业选手的程序——AlphaGo,后者能够通过机器学习的方式掌握比赛技巧。
而同样,在今天国际顶尖期刊《自然》报道了谷歌所开发的这款新围棋AI。这款名为AlphaGo(翻译为阿尔法围棋)的人工智能,在没有任何让子的情况下以5:0完胜欧洲冠军,职业围棋二段樊麾,樊麾出生于中国,目前是法国国家围棋队总教练,已经连续三年赢得欧洲围棋冠军的称号。

AlphaGo与欧洲围棋冠军樊麾的5局较量
除此之外,研究者也让AlphaGo和其他的围棋AI进行了较量,在总计495局中只输了一局,胜率是99.8%。它甚至尝试了让4子对阵Crazy Stone,Zen和Pachi三个先进的AI,胜率分别是77%,86%和99%。
计算机和人类竞赛在棋类比赛中已不罕见,在三子棋、跳棋和国际象棋等棋类上,计算机都先后完成了对人类的挑战。根据资料显示,1997年,国际象棋AI第一次打败顶尖的人类;2006年,人类最后一次打败顶尖的国际象棋AI;但对拥有2500多年历史的围棋而言,计算机在此之前从未战胜过人类。
AI下围棋,是如何通过计算来打败人类的?
围棋看起来棋盘简单、规则不难。棋盘纵横各19条等距离、垂直交叉的平行线,共构成19×19(361)个交叉点。比赛双方交替落子,目的是在棋盘上占据尽可能大的空间。围棋最大有3^361 种局面,大致的体量是10^170,而已经观测到的宇宙中,原子的数量才10^80。国际象棋最大只有2^155种局面,称为香农数,大致是10^47。
那么AI是如何攻破人类的呢?根据果壳网上作者“开明”的文章解释,面对任何棋类,一种直观又偷懒的思路是暴力列举所有能赢的方案,这些方案会形成一个树形地图。AI只要根据这个地图下棋就能永远胜利。
然而,围棋一盘大约要下150步,每一步有250种可选的下法,所以粗略来说,要是AI用暴力列举所有情况的方式,围棋需要计算250^150种情况,大致是10^360。相对的,国际象棋每盘大约80步,每一步有35种可选下法,所以只要算35^80种情况,大概是10^124。无论如何,枚举所有情况的方法不可行,所以研究者们需要用巧妙的方法来解决问题,他们选择了模仿人类大师的下棋方式。
机器学习研究者们祭出了终极杀器——“深度学习”(Deep Learning)。深度学习是目前人工智能领域中最热门的科目,它能完成笔迹识别,面部识别,驾驶自动汽车,自然语言处理,识别声音,分析生物信息数据等非常复杂的任务。
AlphaGo 的核心是两种不同的深度神经网络。“策略网络”(policy network)和 “值网络”(value network)。它们的任务在于合作“挑选”出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围里,本质上和人类棋手所做的一样。
其中,“值网络”负责减少搜索的深度——AI会一边推算一边判断局面,局面明显劣势的时候,就直接抛弃某些路线,不用一条道算到黑;而“策略网络”负责减少搜索的宽度——面对眼前的一盘棋,有些棋步是明显不该走的,比如不该随便送子给别人吃。将这些信息放入一个概率函数,AI就不用给每一步以同样的重视程度,而可以重点分析那些有戏的棋着。
AlphaGo利用这两个工具来分析局面,判断每种下子策略的优劣,就像人类棋手会判断当前局面以及推断未来的局面一样。这样AlphaGo在分析了比如未来20步的情况下,就能判断在哪里下子赢的概率会高。
研究者们用许多专业棋局训练AI,这种方法称为监督学习(supervised learning),然后让AI和自己对弈,这种方法称为强化学习(reinforcement learning),每次对弈都能让AI棋力精进。然后他就能战胜冠军啦!
人类在下棋时有一个劣势,在长时间比赛后,他们会犯错,但机器不会。而且人类或许一年能玩1000局,但机器一天就能玩100万局。所以AlphaGo只要经过了足够的训练,就能击败所有的人类选手。
被打败的欧洲冠军樊麾是什么样的水平?
值得注意的是,在AlphaGo打败欧洲冠军之后,谷歌同时还宣布将在今年三月挑战韩国围棋选手李世石,李世石是围棋九段高手,也是近10年来获得世界第一头衔最多的棋手,谷歌为此提供了100万美元作为奖金。
根据谷歌自己的评估,目前AlphaGo的实力只在职业二段左右,其打败的欧洲冠军也只有二段,而韩国围棋选手李世石却是九段,无疑二段与九段之间的实力甚为悬殊。李世石对谷歌的这一挑战表示非常期待,并且认为自己一定会赢。
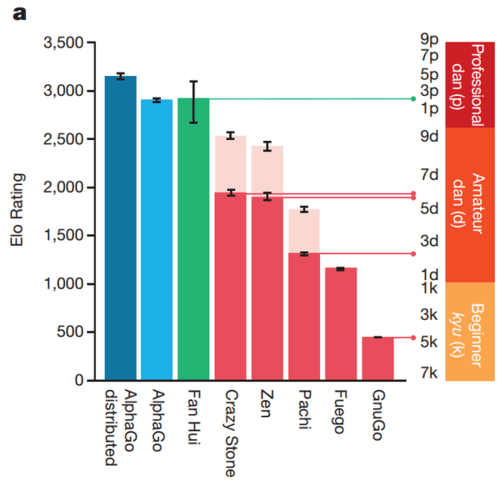
同时,知乎上有匿名用户分析:
如上图,欧洲冠军Hui Fan的水平目测是二段左右,而最强的AlphaGo distributed大概是五段,这和“击败人类”的目标还有点距离(其他非随机类游戏,机器都能轻松击败最强的人类大师)。所以还是等三月和李世石的五番棋吧。
尽管AlphaGo尚有一个月时间学习,但是假设围棋的技巧是有限的话,无论是人学习还是机器学习一定是一条渐近线,即使AlphaGo在三月的挑战中输了这场比赛,这仍旧是AI发展史中一件极具标志性的事情。
PS:本文分析部分内容综合自果壳专栏、知乎用户,点击链接可产看原回答,更多观点可见钛媒体文章《人工智能如何一步步走来,直到挑战欧洲围棋冠军》